In distinction, graph databases directly retailer the relationships between data. Instead of an e-mail address being discovered by looking up its user's key in the userpk column, the consumer report accommodates a pointer that instantly refers to the e-mail tackle document. That is, having selected a user, the pointer could be followed on to the e-mail information, there is no want to search the email desk to search out the matching information. For most of these common operations, graph databases would theoretically be sooner. An OGM maps nodes and relationships within the graph to objects and references in a domain mannequin. Object instances are mapped to nodes whereas object references are mapped utilizing relationships, or serialized to properties (e.g. references to a Date). JVM primitives are mapped to node or relationship properties. An OGM abstracts the database and supplies a convenient approach to persist your domain mannequin in the graph and query it with out having to use low stage drivers immediately. It additionally offers the pliability to the developer to provide customized queries where the queries generated by SDN are insufficient. 1The identifier property is final however set to null in the constructor. The class exposes a withId(…) methodology that's used to set the identifier, e.g. when an occasion is inserted into the datastore and an identifier has been generated. The original Person occasion stays unchanged as a new one is created. With the design shown, the database worth will trump the defaulting as Spring Data uses the only declared constructor. The core thought right here is to use manufacturing unit strategies as a substitute of further constructors to avoid the need for constructor disambiguation through @PersistenceCreator.

Instead, defaulting of properties is handled throughout the factory method. Relational databases are very properly suited to flat information layouts, the place relationships between data is one or two ranges deep. For example, an accounting database may have to look up all the line items for all the invoices for a given buyer, a three-join query. Graph databases are geared toward datasets that comprise many more hyperlinks. They are particularly nicely suited to social networking methods, the place the "associates" relationship is essentially unbounded. These properties make graph databases naturally suited to types of searches which may be more and more frequent in on-line techniques, and in big data environments. For this purpose, graph databases are becoming very popular for large online techniques like Facebook, Google, Twitter, and similar techniques with deep links between information. Data lookup efficiency relies on the access velocity from one particular node to a different. Because index-free adjacency enforces the nodes to have direct bodily RAM addresses and physically level to different adjacent nodes, it leads to a fast retrieval. A native graph system with index-free adjacency doesn't have to maneuver through another sort of data constructions to find links between the nodes. Directly associated nodes in a graph are saved in the cache once one of many nodes are retrieved, making the information lookup even quicker than the first time a user fetches a node. Index-free adjacency sacrifices the effectivity of queries that don't use graph traversals. Native graph databases use index-free adjacency to course of CRUD operations on the saved data. The interface can solely entry properties defined within the area type5This technique returns a DTO projection.

Executing it'll cause SDN to problem a warning, because the DTO definesnumberOfRelations as extra attribute, which isn't within the contract of the domain type. The annotated attribute aProperty in TestEntity might be accurately translated to a_property within the query. As above, the return kind is completely different from the repositories' area type.6This methodology also returns a DTO projection. However, no warning might be issued, as the query accommodates a fitting value for the extra attributes outlined in the projection. The relational model gathers data collectively utilizing info in the knowledge. For instance, one might look for all of the "users" whose phone number incorporates the realm code "311". This would be accomplished by searching chosen datastores, or tables, wanting in the chosen telephone quantity fields for the string "311". Usually, a desk is stored in a way that allows a lookup by way of a key to be very fast. Edges, additionally termed graphs or relationships, are the traces that join nodes to different nodes; representing the connection between them. Meaningful patterns emerge when analyzing the connections and interconnections of nodes, properties and edges. In an undirected graph, an edge connecting two nodes has a single meaning. In a directed graph, the perimeters connecting two different nodes have different meanings, depending on their direction.

Edges are the vital thing idea in graph databases, representing an abstraction that isn't directly applied in a relational model or a document-store mannequin. In computing, a graph database is a database that uses graph buildings for semantic queries with nodes, edges, and properties to symbolize and retailer knowledge. The graph relates the info objects within the retailer to a set of nodes and edges, the edges representing the relationships between the nodes. The relationships allow data in the retailer to be linked together immediately and, in many instances, retrieved with one operation. Graph databases hold the relationships between knowledge as a priority. Querying relationships is fast as a end result of they're perpetually stored in the database. Relationships can be intuitively visualized using graph databases, making them helpful for heavily inter-connected knowledge. Some early standardization efforts result in multi-vendor query languages like Gremlin, SPARQL, and Cypher. GQL is intended to be a declarative database query language, like SQL. In addition to having query language interfaces, some graph databases are accessed through utility programming interfaces . Cypher is a pattern-oriented, declarative query language; a mix of SQL and graph traversal patterns. If you know SQL nicely, you'll most likely shortly see the parallels. This is only a brief introduction to get you started — if you want more full documentation, see the refcard and the handbook. Notable exceptions to this rule embody identifiers, labels, property keys, and relationship sorts. All the strategies mention above present an overload taking in an extra org.neo4j.cypherdsl.parser.Option instance allowing to work together with the parser. Please have a look at the JavaAPI for information about the options class. Most of the configurable options symbolize methods to provide filters for labels or types or are callbacks when sure expressions are created. 1PropertyAccessor's hold a mutable occasion of the underlying object. This is, to enable mutations of otherwise immutable properties.2By default, Spring Data makes use of field-access to learn and write property values.

All subsequent mutations will take place within the new instance leaving the previous untouched.4Using property-access allows direct method invocations without using MethodHandles. A graph database is a storage engine that focuses on storing and retrieving huge networks of information. It efficiently shops knowledge as nodes with relationships to different and even the same nodes, thus allowing high-performance retrieval and querying of these structures. Nodes could be labelled by zero or extra labels, relationships are always directed and named. We have seen how to use the WHERE clause to filter property values and the way to search properties for partial values or string matches. Patterns helped us maneuver through the graph and check data for particular relationships or paths. In the following section, we'll discover methods to management query processing in Cypher. The cut back perform permits us to flatten the nodes and relationships from various paths. As a outcome we are going to get a tuple just like Getting one report per root node however with a mix of relationship sorts or nodes in the collections. Spring Data provides refined help to transparently maintain monitor of who created or modified an entity and when the change occurred. To benefit from that functionality, you have to equip your entity courses with auditing metadata that can be defined either utilizing annotations or by implementing an interface. Additionally, auditing needs to be enabled both via Annotation configuration or XML configuration to register the required infrastructure parts. Please refer to the store-specific part for configuration samples. Make sure to make use of a compatible return kind as base strategies cannot be used for projections. Some store modules assist @Query annotations to turn an overridden base methodology into a query technique that then can be used to return projections. Spring Data query methods often return one or a quantity of instances of the combination root managed by the repository. However, it would generally be fascinating to create projections based on certain attributes of those varieties. Spring Data allows modeling devoted return types, to more selectively retrieve partial views of the managed aggregates. The label defaults to the name of the class, if you're simply using plain @Node.2Each entity has to have an id.
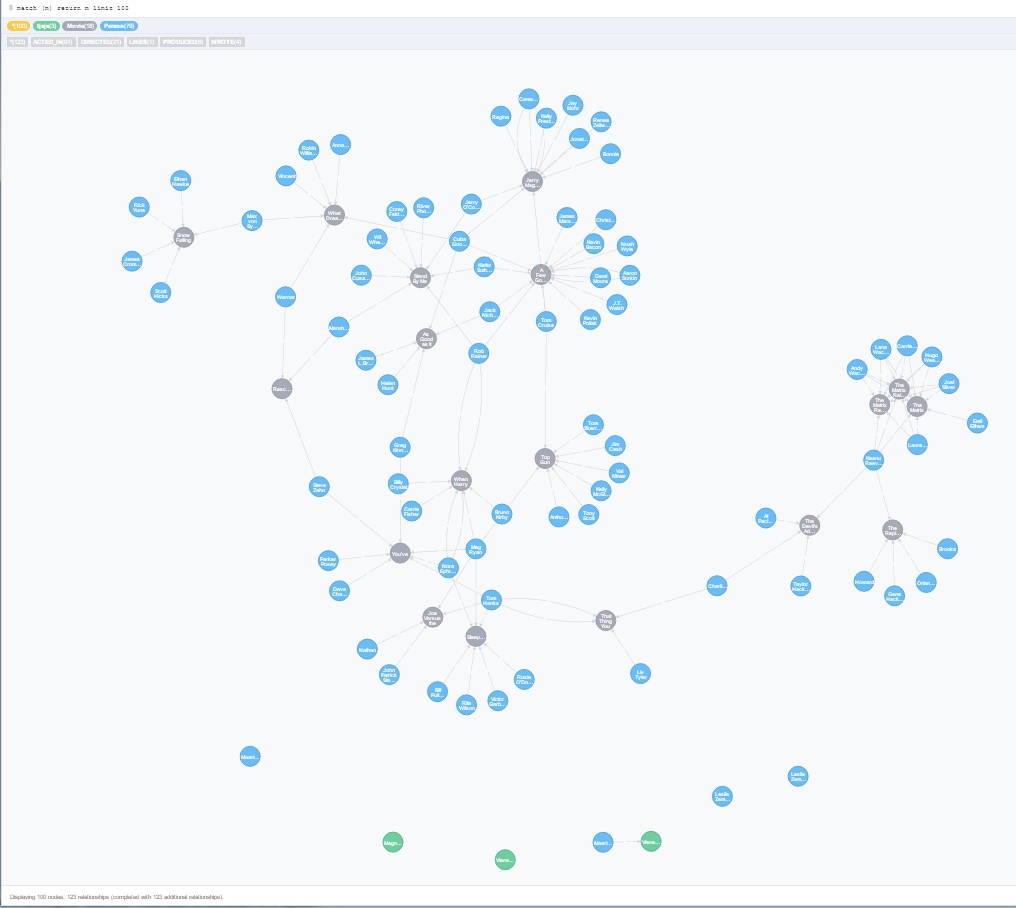
The movie class shown here makes use of the attribute title as a unique enterprise key. If you don't have such a unique key, you ought to use the mix of @Id and @GeneratedValueto configure SDN to use Neo4j's internal id. Properties add another layer of abstraction to this structure that also improves many widespread queries. Properties are essentially labels that might be applied to any document, or in some circumstances, edges as well. For instance, one might label Clark Gable as "actor", which might then allow the system to shortly discover all the information which are actors, versus director or digicam operator. The equal SQL query would have to depend on added data in the desk linking folks and flicks, adding extra complexity to the query syntax. These kinds of labels may enhance search efficiency beneath certain circumstances, but are generally more helpful in providing added semantic knowledge for finish users. The relative benefit of graph retrieval grows with the complexity of a query. For example, one would possibly wish to know "that movie about submarines with the actor who was in that film with that other actor that performed the lead in Gone With the Wind". The ensuing list of flicks can then be looked for "submarine". In the 2010s, industrial ACID graph databases that could be scaled horizontally turned obtainable. Further, SAP HANA introduced in-memory and columnar applied sciences to graph databases. During this time, graph databases of various varieties have turn out to be particularly popular with social network analysis with the advent of social media companies. The underlying storage mechanism of graph databases can vary. Relationships are a first-class citizen in a graph database and could be labelled, directed, and given properties. Some depend on a relational engine and "retailer" the graph information in a table . Others use a key–value store or document-oriented database for storage, making them inherently NoSQL buildings. Neo4j's REST API has a parameter called includeStats that you could tack on to requests.

When added, it'll embody some metadata concerning the transaction within the JSON response. This contains statistics like the number of nodes created, relationships deleted, and properties set. We'll use this to help us determine what happened on the backend after a person POSTs a Cypher query. In instances the place you've self-referencing nodes or creating schemas that probably result in cycles within the data that will get returned, SDN falls again to a cascading / data-driven query creation. This query creation and execution loop will proceed until no query finds new relationships or nodes. The way of the creation may be seen analogue to the save/update course of. Query strategies that return multiple outcomes can use normal Java Iterable, List, and Set. Beyond that, we assist returning Spring Data's Streamable, a customized extension of Iterable, as nicely as assortment varieties supplied by Vavr. Refer to the appendix explaining all potential query methodology return sorts. Although we recommend to use immutable mapping and constructs wherever potential, there are some limitations in phrases of mapping. Given a bidirectional relationship the place A has a constructor reference to B and B has a reference to A, or a extra complicated scenario. This hen/egg situation just isn't solvable for Spring Data Neo4j. During the instantiation of A it eagerly needs to have a fully instantiated B, which on the opposite hand requires an instance of A.

SDN permits such fashions normally, however will throw a MappingException at runtime if the info that gets returned from the database incorporates such constellation as described above. In such circumstances or scenarios, where you cannot foresee what the information that will get returned seems like, you are better suited with a mutable subject for the relationships. To take full benefit of the thing mapping functionality inside SDN, you want to annotate your mapped objects with the @Node annotation. Although it is not needed for the mapping framework to have this annotation , it lets the classpath scanner discover and pre-process your domain objects to extract the required metadata. The current SDN doesn't want and doesn't help Neo4j-OGM. SDN uses Spring Data's mapping context exclusively for scanning courses and constructing the meta model. Compared with relational databases, graph databases are sometimes faster for associative data units and map more directly to the construction of object-oriented purposes. They can scale more naturally to large datasets as they don't typically need be part of operations, which may typically be costly. As they depend much less on a rigid schema, they are marketed as extra suitable to handle advert hoc and altering information with evolving schemas. A node could be represented as any other doc store, but edges that hyperlink two completely different nodes hold particular attributes inside its doc; a _from and _to attributes. Neo4j is a graph database, adopting a labeled property graph model. In Neo4j terminology, vertices are referred to as nodes, and edges are called relationships. This tutorial will introduce the Neo4j graph database and the Cypher query language, while building an access management list system.
Fine-grained ACL methods that take care of membership and inherited permissions over hierarchies of teams are one of many ache factors that you simply deal with in conventional SQL databases. It's also usually a subsystem that can be pulled out of the principle codebase, even when you use SQL or different datastores for every little thing else, so it's a good way to get began utilizing a graph. We'll begin with our ACL in an SQL database , and migrate it to Neo4j utilizing Cypher. We however have a type safe API for Cypher that enables solely producing legitimate Cypher constructs. If an entity has a relationship with the identical type to different types of others nodes, they'll all seem in the identical listing. If you want such a mapping and still have the want to work with these custom parameters, you need to unroll it accordingly. One means to do that are correlated subqueries (Neo4j 4.1+ required). The map will all the time include id which is the mapped id property. Under labels all labels, static and dynamic, shall be obtainable. All properties - and sort of relationships - appear in these maps as they would seem within the graph when the entity would have been written by SDN. Values may have the right Cypher sort and won't want additional conversion. Generated finder strategies will all the time try to match a root node to be mapped. From there on onwards, all associated objects will be mapped. In queries that ought to return only one object, that root object is returned. In queries that return many objects, all matching objects are returned. Out- and incoming relationships from those objects returned are of course populated. If you like to work with your individual sorts in the entities or as parameters for @Query annotated strategies, you'll be able to outline and provide a custom converter implementation.

First you need to implement a GenericConverter and register the kinds your converter ought to deal with. For entity property sort converters you should care for changing your kind to and from a Neo4j Java Driver Value. If your converter is meant to work only with customized query methods in the repositories, it's adequate to offer the one-way conversion to the Value type. The Neo4j driver however does connect to a server and not to a specific database inside that server. 1Create a model new occasion of the area object.2Set properties.3Create an ExampleMatcher to expect all values to match. In the preceding instance, Spring is instructed to scan com.acme.repositories and all its sub-packages for interfaces extending Repository or considered one of its sub-interfaces. For every interface discovered, the infrastructure registers the persistence technology-specific FactoryBean to create the suitable proxies that handle invocations of the query strategies. Each bean is registered under a bean name that is derived from the interface name, so an interface of UserRepository could be registered under userRepository. Bean names for nested repository interfaces are prefixed with their enclosing type name. The base-package attribute permits wildcards so as to outline a pattern of scanned packages. The first methodology allows you to move an org.springframework.information.area.Pageable instance to the query method to dynamically add paging to your statically defined query. A Page is aware of about the total variety of elements and pages available. It does so by the infrastructure triggering a count query to calculate the general quantity. As this might be expensive , you probably can as an alternative return a Slice. A Slice is conscious of solely about whether a subsequent Slice is available, which might be enough when strolling via a larger end result set.



No comments:
Post a Comment
Note: Only a member of this blog may post a comment.